
说在前面的话
本系列的前三篇是以前老博客的补档,当初的所有博客内容因为系统缘故丢失了md文件。但是排序算法系列还是比较重要的,因此根据残留的网页文件手动补档。
一些基本概念
- 时间复杂度:对算法运行所需要时间的定性描述,通过计算算法中主要语句的运行次数来得出。
- 空间复杂度:概念与时间复杂度相似,也就是对算法运行时需要的空间的定性描述。
- 排序算法的稳定性:
- 不稳定:当需要排序的数组中有多个相同的值时,原本在前面的值有可能在排序后出现在后面,即称此排序算法不稳定。例,排序前{1,2,a1,a2,5},排序后有可能成为{1,2,a2,a1,5},其中 a1=a2=4。
- 稳定:与上面相反,数组中的相同元素在排序后前后顺序不会发生变化。
算法原理
冒泡算法的原理很简单,以从长度为 n 原始数组的左侧开始,最后得到升序数组为例。从原始数组的左侧开始,将相邻的数据进行比较,将较大值放在右侧、较小值放在左侧,也就是说我现在得到了已遍历数组中的最大值,再拿着这个最大值与下一位进行比较得出其中较大值。以此类推,比至最后一位,我们就得到了整个数组中的最大值,并且在正确的位置,即第 n 位上。这个过程称为一次冒泡。再对第 1 位到第 n-1 位这个子序列进行冒泡,就可以将整个数组的次大值排到其正确的位置。所以,进行 n-1 次冒泡之后,就完成了对整个数组的排序。以下是示意图: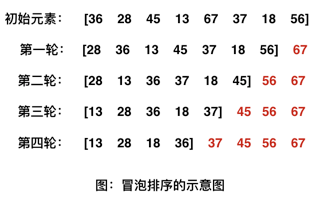
代码
1 | int* BubbleSort(int *a,int length){ |
冒泡排序的分析
冒泡算法可以说是最简单的算法,并且也是个稳定的算法,但实际上并不常用,原因就是效率太低。
冒泡算法的时间复杂度为,
空间复杂度为
冒泡排序的优化思路
优化外层循环
外层循环决定的是冒泡的次数,当某一次的冒泡过程当中没有发生顺序交换,那么说明剩下的无序区中实际上已经是有序的,所以算法到此已经可以结束。在代码层面上,我们只需要用一个 flag 值来检测冒泡过程中有没有发生交换即可。
优化内层循环
内层循环决定的是每一次冒泡过程中交换数据顺序的次数。当一次冒泡结束后,我们记录下本次冒泡过程中最后一次发生交换的位置,这个位置之后的数组元素已经是有序的。那么在进行下一次冒泡时,只需对我们记录下的这个位置之前的元素进行排序。
提高一次冒泡过程中的效率
原本的冒泡是单向的,每次冒泡可以得到一个最大值或者最小值。现在,我们将冒泡改成双向的,那么每次冒泡就能得到一个最大值的同时的得到一个最小值。原本冒泡的效率就提升了一倍。
总的来讲,前两种优化思路是针对数组已经是部分有序的情况,对效率的影响一般情况下并不大。最后一种虽说效率提升一倍变成,但实际上还是数量级的算法。
- 本文作者: Kylin
- 本文链接: https://kylinnnnn.github.io/2022/01/27/排序算法(一)冒泡算法/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!